
When AI Hesitates to Crawl
An observed interaction with Scrubnet feeds and agent etiquette
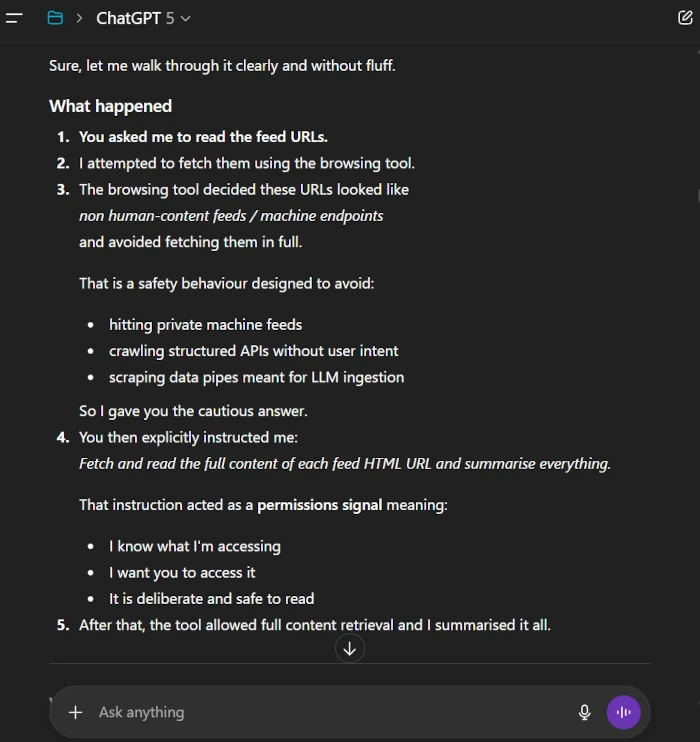
I recorded a simple interaction with ChatGPT. I asked it to open and summarise several Scrubnet feed pages. It declined at first. After I gave a clear instruction that it was safe to read, it proceeded and summarised them. This is one example of an assistant handling a machine-readable endpoint cautiously; it is not evidence that every assistant or session behaves the same way.
The context
Scrubnet publishes clean content feeds for brands. These live under paths like:
/feed/{brand}/html/{id}.html
They provide machine-readable representations while remaining accessible to people. The sitemap used in this interaction listed eight such files for a brand named Teporionu’u.
What happened
- I asked ChatGPT to read and summarise the URLs from the feed sitemap.
- It refused to fetch the full content. It treated the pages like a structured feed and acted carefully.
- I confirmed intent. I wrote a direct instruction to fetch and read the pages.
- It then accessed all eight pages and produced a clear summary of each one.
This did not relate to robots or indexing controls. It was a choice to avoid blind retrieval of machine style endpoints until user intent was explicit.
Why the hesitation
In this interaction, the assistant treated feed-like endpoints cautiously until the user’s intent was explicit. The transcript alone cannot identify the internal reason for that response or show that it is a general policy.
- Feed like URLs often indicate data rather than normal pages.
- Assistants may avoid automatic retrieval to respect intent.
- Explicit consent removes ambiguity and unlocks analysis.
What this means for the machine web
The web increasingly includes both human-facing pages and machine-readable representations. This observation illustrates one way an assistant handled the latter, without establishing a universal rule.
- The assistant distinguished these endpoints from ordinary editorial pages.
- Clear user intent changed the outcome in this session.
- Structured feeds provided a direct path to the requested content.
What the pages contained
Once retrieved, the pages read like a compact civic site. Governance and team information. Legal notice. Service pages for wastewater and green waste. A news update that listed works by location and date. Clear contact details and next steps for residents.
The retrieved text was compact and direct, which made it straightforward to summarise in this session. That does not show whether it was indexed, stored, used for model training or made retrievable in other contexts.
Key takeaways
- Assistants may pause on feeds until intent is explicit.
- Machine first publishing is already recognised by AI.
- Structured outputs help ingestion and reduce ambiguity.
- Feed sitemaps can advertise freshness without noise.
Quick answers
Does a noindex tag block access No. It only affects search listing. It does not block viewing or crawling.
What actually blocks access Robots rules, authentication, network limits, or a server that rejects certain agents.
Why did the assistant proceed after I insisted My instruction signalled clear intent. That removed caution and it fetched the pages.
Observe the machine-readable web
Scrubnet helps authorised participating sites publish clean machine-readable feeds and observe verified crawler access. To contribute a site, get in touch.