SEO Scrubbox
Compare source and rendered SEO signals, test indexability, inspect bot access and run technical diagnostics directly in Chrome.

Practical tools and technical insight for people who build and optimise the web
Scrubnet is an independent toolkit and knowledge hub for technical SEO specialists and web developers. It brings together focused apps, practical articles and first-hand crawler data to make complex work easier to inspect, organise and understand.
SEO Scrubbox and ScrubGraph are the first Scrubnet apps. They support different parts of a technical workflow, and the collection will grow as new, useful ideas are developed.
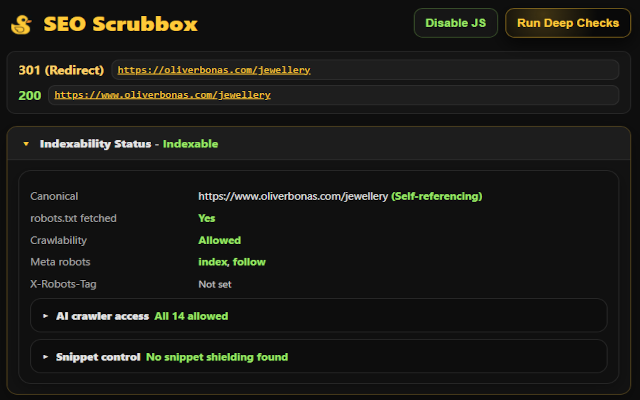
Compare source and rendered SEO signals, test indexability, inspect bot access and run technical diagnostics directly in Chrome.
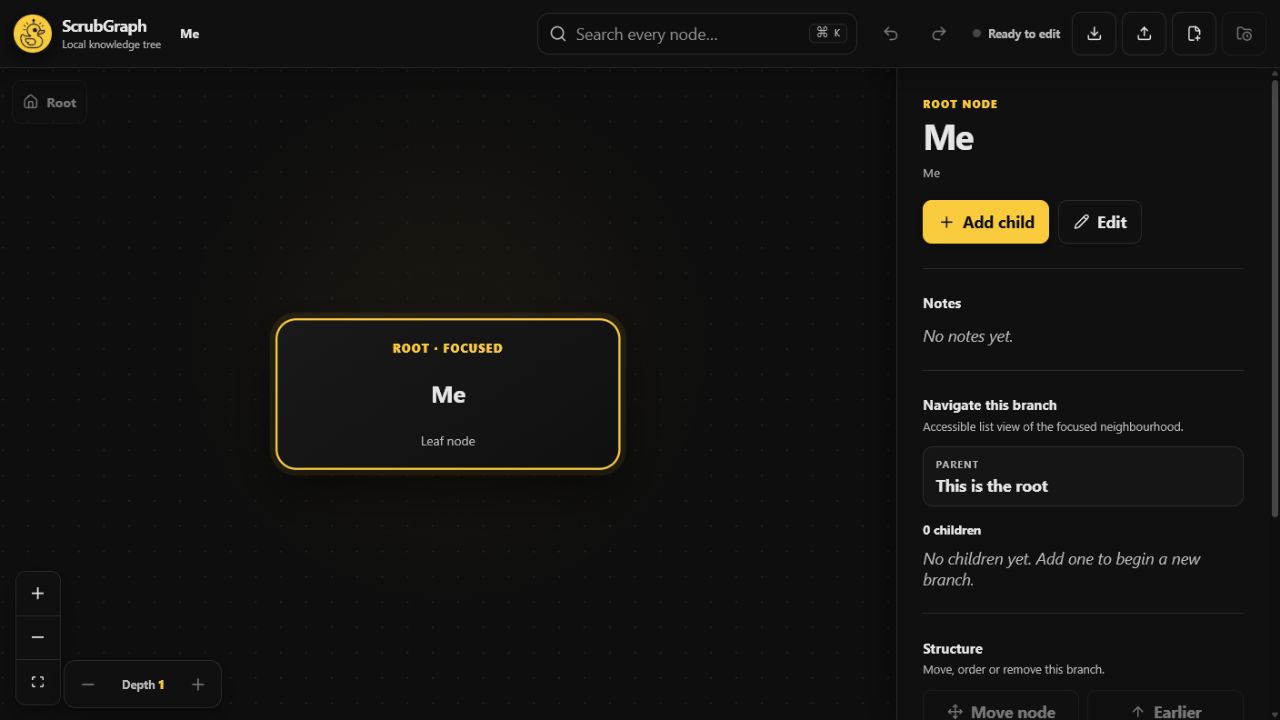
Build and navigate private visual knowledge trees with Markdown notes, flexible editing, search and portable branch or full-graph exports.
Scrubnet publishes practical articles about technical SEO, web development, AI search and crawler behaviour. Some explain better ways of working; others turn experiments and observed data into careful, useful analysis.
The observatory is Scrubnet’s live research layer. It records how recognised search and AI crawlers request authorised machine-readable feeds, providing public data for descriptive analysis of discovery, recrawling, freshness and format choices. Requests show access behaviour, not indexing, ranking or citation.
Understand the research environment, its methods and how to interpret the data.
Filter recent requests by crawler, path, format, response and date.
Explore request timing, content age and crawler distribution visually.
Inspect the machine-readable feeds behind the observation environment.
Scrubnet was founded by Charles Vayssié, a technical SEO specialist and web developer who leads strategy and delivery across complex e-commerce and international websites. His work spans migrations, rendering, site architecture, performance, structured data and international SEO, with technical findings translated into practical engineering roadmaps.

Add an authorised site to broaden the crawler dataset, suggest a technical topic, or collaborate with Scrubnet on an analysis, case study or useful way of working.
Observatory participation is free: add a website with up to 50,000 public URLs. There are no visibility or ranking guarantees.
Want to contribute to the crawler research? Add an authorised site.
Or reach out at contact@scrubnet.org