
AI Ingestion & Visibility Technical Guidelines
A practical guide to making website content easier for AI crawlers, retrieval systems, and autonomous agents to access, understand, and reference accurately.
AI visibility is becoming a distinct part of technical SEO. It still depends on familiar foundations such as crawlability, indexability, performance, structured data, and content quality, but it introduces new requirements around machine extraction, AI bot behaviour, retrieval systems, answer generation, and server-side measurement.
AI platforms do not all consume websites in the same way. Some crawl large sections of the web, some fetch pages only when a user asks a question, some rely heavily on existing search indexes, and others behave more like browser-based agents. The practical goal is to make the website easy to retrieve, parse, summarise, validate, and cite across these different systems.
The guidance below focuses on the areas that most often affect whether AI systems can access content cleanly and use it with confidence.
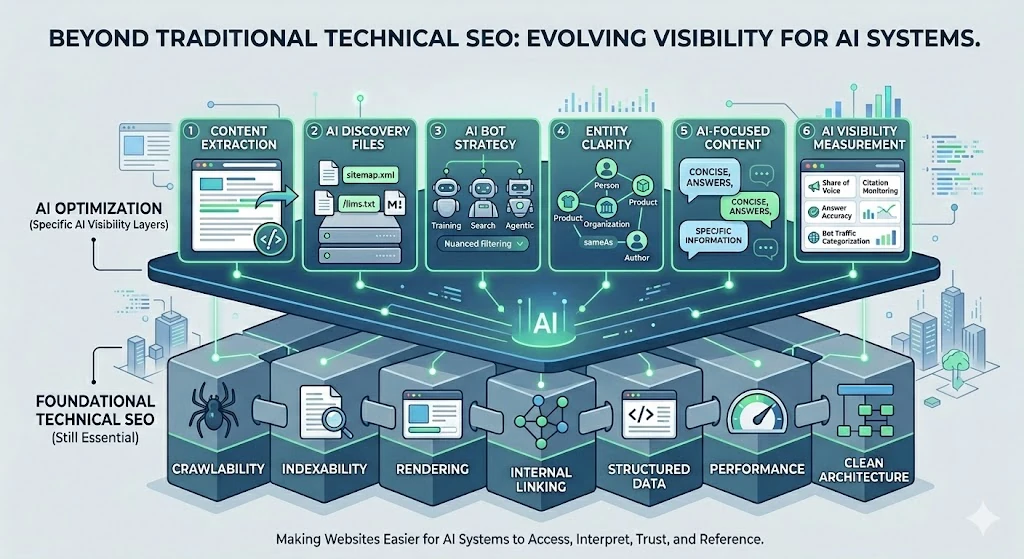
Make the core content easy to extract
The first requirement for AI ingestion is simple: the important content and technical signals must be available without unnecessary friction. Primary copy, internal links, canonical tags, metadata, and structured data should be present in the initial HTML response wherever possible.
Use server-rendered or statically generated HTML
Do not make essential content depend entirely on client-side JavaScript. Some AI crawlers and retrieval systems can render JavaScript, but this should not be assumed. Rendering adds cost, increases delay, and creates more opportunities for important signals to be missed.
Use semantic page structure
Well-organised HTML helps AI systems identify the main topic, understand section hierarchy, split content into useful chunks, and cite the correct part of a page.
<main>
<article>
<section>
<h1>Page topic</h1>
<h2>Section topic</h2>
<p>Clear answer text.</p>
</section>
</article>
</main>Keep important information visible by default
Avoid placing key text, links, product details, specifications, prices, policies, or supporting information only inside JavaScript-dependent tabs, accordions, filters, carousels, or load-more experiences. Interactive components are fine, but the content should still be present in the HTML where possible.
Reduce low-value HTML noise
AI systems often process pages within limited context windows. Repeated boilerplate, excessive navigation copy, injected app content, duplicated blocks, and script-heavy markup can reduce the signal-to-noise ratio. Keep templates clean and make the main content easy to isolate.
Write content that can support useful AI answers
AI visibility is not only a crawling problem. A page also needs to answer real questions clearly enough for an AI system to summarise, compare, recommend, or cite it accurately.
Use an answer-led format
Start pages and key sections with the direct answer or summary, then add the supporting detail. This makes the page easier to understand quickly while still giving AI systems enough context to avoid oversimplifying the topic.
Create pages around decision-making needs
Useful AI-facing content often answers high-intent questions such as:
- What is X?
- How does X work?
- How much does X cost?
- Is X suitable for Y?
- How to choose X
- X vs Y
- Best X for Y
- Common problems with X
- Alternatives to X
These pages should be genuinely helpful and specific. Thin pages created only to target prompt patterns are unlikely to provide strong long-term value.
Support comparisons and recommendations
AI answers frequently compare products, brands, providers, features, and suitability. Support this with comparison tables, use-case guidance, pros and cons, pricing explanations, limitations, caveats, and practical recommendations.
Make the brand and offer unambiguous
The website should clearly explain who the organisation is, what it provides, who it is for, where it operates, what makes it different, and what proof supports its claims.
Avoid claims that cannot be verified
Claims such as best, leading, number one, or most trusted should be backed by evidence. Awards, independent reviews, certifications, customer data, and credible third-party references can help AI systems assess whether a claim is supportable.
Provide machine-readable discovery paths
Traditional discovery files still matter, but AI systems may also benefit from curated files that explain the website, highlight priority content, and provide clean text alternatives to important pages.
Keep XML sitemaps clean
XML sitemaps should contain canonical, indexable URLs only. Remove redirected URLs, noindexed pages, blocked URLs, heavy parameter variations, and pages that canonicalise elsewhere.
Add an llms.txt file where useful
An /llms.txt file can act as a short Markdown guide for AI systems. It can summarise the website and point to the pages or resources that best explain the brand, product, service, documentation, or policies.
- A short description of the website or organisation
- Links to important informational pages
- Links to clean Markdown resources where available
- Notes about which sections are most useful for AI systems
- References to product feeds, documentation, support content, or policy pages where relevant
llms.txt should be treated as an enhancement. It does not replace XML sitemaps, robots.txt, structured data, accessible HTML, or a strong internal linking structure.
Consider curated context files
For some websites, a companion file such as /llms-full.txt or /llms-ctx-full.txt can provide a controlled Markdown version of the most important informational content.
Keep these files tightly scoped. Do not include private, commercially sensitive, outdated, duplicated, or unnecessary content.
Offer Markdown alternatives for key resources
Documentation, support hubs, editorial guides, and long-form resources can benefit from clean Markdown versions that remove layout noise and keep the main content easy to extract.
/page-name.html
/page-name.html.mdStrengthen entities, facts, and structured data
AI systems need consistent facts to understand organisations, products, authors, categories, and relationships. Structured data should reinforce what is visible on the page and reduce ambiguity across the site.
Organisation schema
Use detailed Organization schema across the website. Include the organisation name, URL, logo, contact details, social profiles, founding information where relevant, parent or sub-brand relationships, and sameAs links to trusted external profiles.
Product schema
Ecommerce product schema should be accurate, up to date, and consistent with the visible page and merchant feeds.
- Product name and description
- Product image
- SKU, GTIN, or other identifiers where available
- Brand details
- Price, currency, and availability
- Valid review and aggregate rating data
- Shipping, delivery, and return information where supported
Category and collection pages
Category pages should do more than list items. Add useful descriptive copy, clear headings, internal links, Breadcrumb schema, ItemList schema where appropriate, buying guidance, and FAQs.
FAQ, Q&A, author, and reviewer signals
Use FAQPage and QAPage schema only when the visible page genuinely contains that type of content. For advice-led, editorial, legal, finance, health, or other trust-sensitive content, connect pages to credible author or reviewer profiles.
Freshness signals
When accuracy depends on freshness, expose clear dates in both visible content and structured data. Use datePublished, dateModified, visible last-updated text, and changelog sections where they help users and machines understand when information changed.
Control AI bot access by purpose
Not all AI bots have the same role. Some are used for model training, some support AI search and retrieval, and others fetch pages because a user or agent requested them. Treating all AI bots the same can create unnecessary visibility loss or unnecessary exposure.
Training bots
Training bots crawl content that may be used to train, improve, or evaluate foundation models. Examples include GPTBot, ClaudeBot, CCBot, and anthropic-ai.
Allow or block these bots based on intellectual property, licensing, legal, and commercial strategy.
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: CCBot
Disallow: /AI search and retrieval bots
These bots are more directly connected to AI answer visibility, search inclusion, citations, and live retrieval. Examples include OAI-SearchBot, PerplexityBot, YouBot, and Applebot-Extended.
If the goal is to appear in AI-generated answers and citations, these bots should usually be allowed.
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /User-triggered and agentic fetchers
Some requests are triggered by a user prompt, custom GPT, browser agent, plugin, or external automation. ChatGPT-User is one example.
This traffic often behaves differently from conventional crawling. Use server-side monitoring, rate limiting, WAF rules, authentication controls, and API safeguards rather than relying on robots.txt alone.
Robots.txt is a policy signal, not a security layer
Robots.txt declares access preferences. It does not enforce them. Use it for signalling, then use logs, verified IPs, WAF rules, and access controls where enforcement is required.
Improve reliability for crawlers and fetchers
AI systems, agents, and crawlers often work with short timeouts and limited tolerance for slow or inconsistent responses. Important pages need to be fast, stable, and predictable.
Technical checks to prioritise
- Fast server response times
- Stable HTML delivery
- CDN caching for HTML where appropriate
- Minimal redirect chains
- Correct HTTP status codes
- Lightweight HTML
- Reliable rendering
- No accidental blocking of important AI retrieval bots
Status code consistency
Important pages should return clean 200 responses. Avoid soft 404s, unnecessary redirects, accidental 403s from bot protection, 5xx errors during crawl spikes, and inconsistent responses by user-agent.
HTTP caching
Use caching headers to reduce repeated downloads and make crawling more efficient. ETag, If-None-Match, Last-Modified, and If-Modified-Since can help crawlers identify unchanged content.
Page and file size
Keep pages and context files concise. For long-form material, use clear sectioning and consider Markdown alternatives for the resources that matter most.
Measure AI visibility beyond standard analytics
Standard analytics only show a limited part of AI visibility. A more complete view combines AI assistant referral tracking, server-side AI bot logging, and prompt-based share of voice measurement.
AI assistant referrals
GA4 can help identify human sessions referred by recognised AI assistants such as ChatGPT, Gemini, Claude, Perplexity, and similar platforms.
This does not capture most crawler activity, training crawls, server-side fetches, or AI systems that consume content without sending a user to the site.
Server-side AI bot logging
Use CDN logs, WAF logs, server access logs, or edge workers to track AI bot activity separately from human sessions.
- Timestamp
- Requested URL
- Status code
- User-agent
- Detected bot name and category
- Referrer where present
- Country or region where appropriate
- Cache status and response time
- HTTP method
- Verified bot status where possible
Avoid exposing raw IP addresses in dashboards unless there is a clear legal basis, suitable access control, and a specific operational reason. For client-facing or public reports, aggregate or anonymise IP-level data.
Useful reporting groups
- Training bots: large-scale crawling that may support model training or improvement.
- AI search and retrieval bots: crawlers connected to answer engines, citations, AI search, or retrieval.
- User-triggered fetchers: requests generated by prompts, custom GPTs, plugins, or browser-like assistants.
- Agentic action bots: bots interacting with APIs, forms, booking journeys, shopping flows, or task-based experiences.
- Unknown or spoofed AI-like traffic: suspicious traffic imitating browsers or known bots but failing verification.
Bot verification
User-agent matching alone is not enough. Where possible, verify known bots using published IP ranges, reverse DNS checks, forward-confirmed reverse DNS, ASN checks, known user-agent patterns, and behavioural signals.
Prompt-based share of voice
Track visibility across major AI platforms using prompts that reflect real customer research behaviour. Measure whether the brand appears, where it appears, sentiment, citations, cited URLs, competitors, answer accuracy, and whether product or pricing information is correct.
Implementation framework
AI visibility work is easiest to manage when it is treated as a continuous technical programme rather than a one-off checklist. A practical rollout can be organised into four workstreams.
1. Access and extraction
Start by making sure AI systems can reach and parse the content that matters most.
- Serve critical content in the initial HTML
- Fix blocked, redirected, noindexed, or unstable priority pages
- Reduce unnecessary HTML noise
- Improve status code consistency
- Check that important AI retrieval bots are not accidentally blocked
2. Understanding and context
Once access is reliable, strengthen the signals that explain what the website, brand, products, and pages mean.
- Improve semantic HTML and heading structure
- Maintain clean XML sitemaps
- Add accurate structured data
- Strengthen sameAs links and entity references
- Create or refine llms.txt and selected Markdown resources
3. Answer usefulness
Then improve the content itself so AI systems can use it to produce clearer and more accurate answers.
- Add answer-led summaries to important pages
- Create useful comparison and decision content
- Clarify product, service, pricing, and suitability information
- Add evidence for strong claims
- Improve freshness signals where accuracy changes over time
4. Measurement and governance
Finally, measure activity and review policies regularly so the strategy can adapt as AI platforms change.
- Track AI assistant referrals
- Build server-side AI bot reporting
- Verify known bots where possible
- Monitor prompt-based share of voice
- Review cited URLs, competitors, and answer accuracy
- Update robots.txt and AI bot rules when strategy changes
Key takeaways
- AI visibility depends on whether content can be accessed, extracted, understood, and cited.
- Server-rendered, semantic HTML reduces the risk of important information being missed.
- XML sitemaps, llms.txt, context files, and Markdown alternatives can all support machine-readable discovery.
- AI bots should be managed by purpose, especially when separating training, retrieval, user-triggered, and agentic activity.
- Structured data and entity consistency help AI systems connect facts across pages and sources.
- Useful, answer-led content is more likely to support accurate AI summaries and citations.
- Server-side logging is essential because analytics platforms only capture part of AI visibility.